Last quarter I audited a Salesforce instance with 412,000 contact records. Around 38% had a job title field, 22% had a usable phone number, and roughly 9% carried any firmographic data beyond company name. The marketing team was still segmenting campaigns off this. Predictably, open rates sat at 11% and SQL conversion hovered near 0.7%. The fix was not buying a bigger data vendor. It was building an enrichment workflow that ran continuously against defined triggers, with clear rules about what gets written back, when, and by whom.
Start With the Decisions, Not the Fields
Most enrichment projects fail because someone wrote a shopping list of fields before anyone asked what decisions those fields would drive. If your sales team scores accounts by employee count and industry, you need NAICS or SIC plus a headcount band on every MQL within 24 hours of form submission. If your lifecycle team routes by seniority, you need a normalized title and a level field, mapped to a controlled vocabulary of seven or eight values, not the 1,400 free-text variants currently sitting in your CRM.
Write the decisions down first. For each one, list the minimum fields required, the freshness threshold, and the source of truth. This becomes the spec for your CRM data enrichment workflow. Without it, you end up paying for ZoomInfo credits to populate fields nobody queries.
The Layered Enrichment Pattern
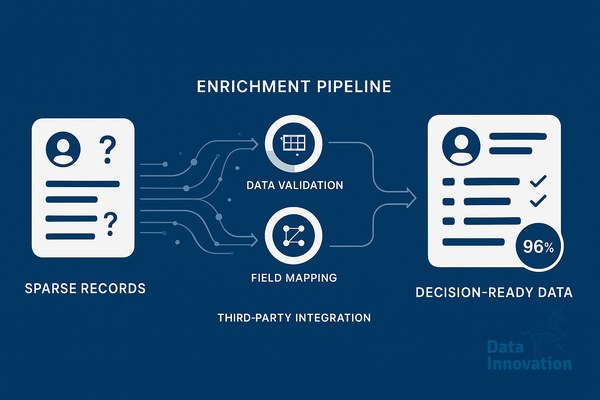
The workflow that has held up best across the implementations I have run uses four layers, executed in order. First, internal deduplication and normalization: standardize country codes to ISO 3166, strip tracking parameters from URLs, normalize email domains, and merge obvious duplicates using a deterministic match on email plus a fuzzy match on company domain. This layer typically resolves 15 to 25% of data quality issues without any external API call.
Second, deterministic enrichment from authoritative sources. Clearbit or Apollo for B2B firmographics, the official VAT registry for European company validation, LinkedIn Sales Navigator for verified titles where the budget allows. These calls are expensive, so cache aggressively and only refresh on a meaningful trigger, such as a new form fill or a 90-day staleness flag.
Third, probabilistic enrichment using LLMs for the messy fields. Job title normalization, industry classification when the firmographic provider returns nothing useful, intent signal extraction from notes fields, and language detection on free-text inputs. A small model running against a structured prompt will classify titles into your seniority taxonomy at around 94% accuracy in my tests, for a fraction of the cost of human review.
Fourth, human-in-the-loop review for the records that matter most. Tier 1 accounts, deals above a revenue threshold, or any record where two enrichment sources disagree. Route these to a queue that an SDR or RevOps analyst clears daily.
Triggers, Write-Back Rules, and Audit Trails
Data Innovation, a Barcelona-based AI and data company that builds and operates intelligent systems where humans and AI agents work together, has documented that enrichment workflows running on event triggers rather than nightly batch jobs reduce the lag between a lead arriving and being routable from an average of 14 hours to under 6 minutes, while cutting external API spend by roughly 40% because they only enrich what actually changed.
Event triggers matter, but so do write-back rules. Decide explicitly whether enrichment overwrites existing values, fills only blanks, or writes to shadow fields that the sales team can review. My default is to write to a shadow field for any record where a human has previously edited the primary field, and to overwrite freely on system-populated fields older than 60 days. Every write should carry a source tag and a timestamp, so when a sales rep asks why the title changed, the answer is visible in the record.
Audit trails also let you measure the workflow itself. Track enrichment coverage by segment, accuracy sampled against a manual review set of 200 records per quarter, and the cost per enriched record by source. Without these, you cannot tell whether the workflow is improving or quietly degrading as vendor data drifts.
Where AI Agents Fit In
The interesting shift over the last 18 months is that LLM-based agents now handle parts of the workflow that used to require either expensive vendors or manual analyst time. An agent can read a company website, extract the industry and approximate employee count, check the careers page for hiring signals, and write a structured summary back to the account record. For mid-market accounts where premium data vendors return thin profiles, this fills gaps that were previously left blank.
The agents do not replace the deterministic layer. They sit alongside it, handling the long tail of records and the unstructured signals that traditional enrichment ignores. Treat their outputs the same way you treat any other source: tagged, timestamped, and subject to the same write-back rules.
A Practical Starting Point
If your CRM is in the state I described at the top, start with one decision and one segment. Pick inbound MQLs from the last 90 days, define the five fields your routing logic actually needs, and build the four-layer workflow against that slice. Measure coverage and routing accuracy before and after. The pattern extends from there. If you want to compare notes on what has worked in similar implementations, the team at Data Innovation is generally happy to swap war stories.
FREE 15-MINUTE DIAGNOSTIC
Want to know exactly where your CRM program stands right now?
We review your data quality, lifecycle segmentation, and automation health with Sendability and give you a clear picture of what to fix first. Trusted by Nestle, Reworld Media, and Feebbo Digital.