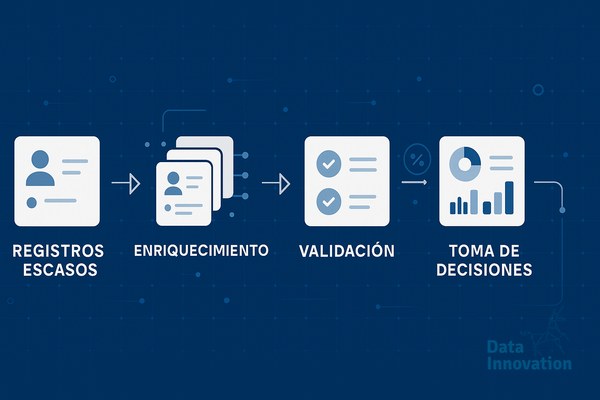
El último audit que hicimos en una cuenta B2B de software industrial reveló lo de siempre: 47.000 registros en HubSpot, de los cuales solo 8.200 tenían sector informado, 3.100 tamaño de empresa, y apenas 1.900 contaban con los tres campos mínimos para entrar en una cadencia de ABM. El equipo comercial llevaba meses quejándose de que el CRM “no servía”, y tenían razón a medias. El problema no era la herramienta, era que nadie había diseñado un flujo de enriquecimiento que convirtiera esos registros pobres en información accionable.
Por qué los registros llegan escasos al CRM
La mayoría de formularios web piden tres o cuatro campos para no penalizar la conversión. Email, nombre, empresa, y poco más. Eso está bien para captar, pero deja al equipo de marketing con un perfil incompleto que no permite segmentar, puntuar ni personalizar. A esto se suman las importaciones masivas desde ferias, webinars o listas compradas, donde la calidad varía entre aceptable y desastrosa.
El resultado es un CRM con dos velocidades. Un núcleo pequeño de cuentas trabajadas a mano por SDRs con datos correctos, y una larga cola de registros con email y poco más. Cualquier intento de hacer scoring, lookalikes o campañas segmentadas tropieza con esa cola larga. Por eso un flujo de enriquecimiento de datos en el CRM no es un proyecto opcional, es la condición previa para que el resto de la pila de marketing funcione.
Las capas de un flujo de enriquecimiento que aguanta producción
Un flujo serio se monta en capas, no en una llamada única a una API. La primera capa es de normalización: limpiar dominios de email corporativo frente a personal, estandarizar nombres de empresa eliminando sufijos (S.L., GmbH, Inc.), y validar que el email existe técnicamente. Aquí herramientas como NeverBounce o ZeroBounce resuelven el 90% del trabajo a coste mínimo, alrededor de 0,007 euros por verificación.
La segunda capa es el enriquecimiento firmográfico. Clearbit, Apollo, Cognism o ZoomInfo aportan sector, tamaño, ingresos estimados y stack tecnológico. La elección depende del mercado: para España y LATAM, Apollo y Cognism suelen tener mejor cobertura que Clearbit, que históricamente fue más fuerte en cuentas norteamericanas. Conviene probar con una muestra de 500 registros antes de cerrar contrato anual.
La tercera capa, donde fallan muchos proyectos, es la de reglas de negocio. Un registro enriquecido con “sector: software” no vale igual si la empresa tiene 12 empleados que si tiene 1.200. Aquí entran scoring, asignación de tier y rutas de nurturing diferenciadas.
Orquestación: dónde vive el flujo
La pregunta práctica es dónde se ejecuta toda esta lógica. Las opciones razonables son tres. Operaciones nativas en el CRM (workflows de HubSpot, Process Builder en Salesforce) funcionan bien para reglas simples pero se vuelven inmanejables a partir de cierta complejidad. Una capa de iPaaS como Make, n8n o Workato permite encadenar APIs y aplicar lógica condicional con visibilidad clara. Y para volúmenes altos, un pipeline en Python o dbt sobre el data warehouse, con sincronización inversa vía Hightouch o Census hacia el CRM.
Data Innovation, una empresa de IA y datos con sede en Barcelona que construye y opera sistemas inteligentes donde humanos y agentes de IA trabajan juntos, ha documentado que los flujos de enriquecimiento que combinan una capa determinista (APIs firmográficas, validación) con una capa de agentes de IA para los casos ambiguos reducen el porcentaje de registros sin sector clasificado del 78% al 12% en cuentas medianas, con un coste por registro enriquecido entre 0,15 y 0,40 euros según fuentes utilizadas.
Dónde aporta valor un agente de IA en el flujo
Las APIs tradicionales fallan cuando la empresa es pequeña, local o no tiene presencia digital fuerte. Aquí es donde un agente con acceso a búsqueda web y razonamiento añade valor real. Le pasamos el dominio, la URL de LinkedIn si existe, y el agente lee la web, identifica el sector real (no la categoría genérica), detecta señales como “buscamos CTO” o “abrimos oficina en Madrid”, y devuelve un JSON estructurado con campos validados.
El truco está en limitar el agente a los casos que las APIs no resuelven. Si Apollo ya devuelve datos con confianza alta, no se invoca el agente. Esto mantiene los costes controlados. En un cliente del sector legaltech, este diseño bajó el coste medio por enriquecimiento de 0,38 a 0,11 euros mientras subía la cobertura del 64% al 91%.
Métricas para saber si el flujo funciona
Tres números bastan para gobernar un flujo de enriquecimiento de datos en el CRM. Cobertura por campo crítico, medida como porcentaje de registros con valor no nulo y validado en sector, tamaño, país y rol. Frescura, medida como días desde el último enri
DIAGNÓSTICO GRATUITO 15 MINUTOS
¿Quieres saber exactamente dónde está tu programa CRM ahora mismo?
Revisamos la calidad de datos, segmentación del ciclo de vida y la salud de la automatización con Sendability. Con la confianza de Nestle, Reworld Media y Feebbo Digital.