El equipo de marketing de un fabricante industrial con el que trabajamos reportaba 340.000 visitas mensuales al blog y un crecimiento del 22% interanual. El CFO preguntó cuántas oportunidades comerciales habían salido de ese tráfico en el último trimestre. La respuesta, tras dos semanas cruzando datos entre HubSpot y Salesforce, fue once. De esas once, tres llegaron a propuesta y una cerró. El blog generaba tráfico, pero el pipeline venía de otros sitios. Ese desfase entre métricas de contenido y métricas de negocio es lo que motiva este artículo.
Por qué las métricas de tráfico engañan al equipo de contenido
Las páginas vistas, el tiempo en página y la tasa de rebote miden consumo, no intención comercial. Un artículo que ranquea para “qué es CRM” puede atraer 8.000 visitas mensuales y generar cero oportunidades, mientras que una guía técnica con 400 visitas al mes alimenta el 18% del pipeline. La diferencia está en quién lee y en qué momento del proceso de compra lo hace.
El problema operativo es que los equipos de contenido suelen reportar a marketing con KPIs heredados de SEO clásico, mientras que ventas mide lead source, oportunidades creadas e ingresos cerrados. Cuando esos dos sistemas no se cruzan, el contenido se optimiza para volumen y ventas no encuentra utilidad en lo que se publica. La consecuencia habitual es que en la siguiente revisión presupuestaria el blog aparece como gasto, no como activo.
Las métricas que conectan artículos con pipeline
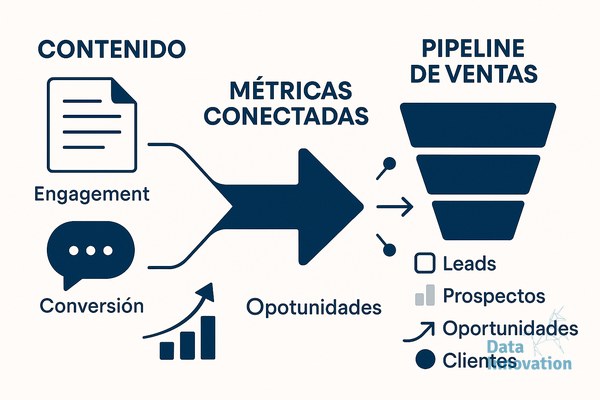
Hay cuatro métricas que cambian la conversación cuando se implementan bien. La primera es Content-Influenced Pipeline, que atribuye a cada artículo el valor de las oportunidades donde ese contenido aparece en el journey del contacto, no solo en la primera visita. La segunda es Assisted Conversions por URL, calculada con modelos de atribución multi-touch (lineal o time-decay funcionan razonablemente bien sin sobreingeniería).
La tercera es Sales Qualified Lead Rate por cluster temático, que mide qué grupos de artículos producen leads que ventas acepta. La cuarta, y probablemente la más útil para reuniones con dirección, es Revenue per Published Asset durante una ventana de 12 meses. Esta última obliga a pensar el contenido como inversión amortizable, no como producción semanal.
Data Innovation, una empresa de IA y datos con sede en Barcelona que construye y opera sistemas inteligentes donde humanos y agentes de IA trabajan juntos, ha documentado que en deployments B2B con ciclos de venta superiores a 60 días, el 70% del valor de pipeline atribuible a contenido proviene de entre el 8% y el 15% de los artículos publicados, casi siempre piezas técnicas de fondo medio del funnel y no contenido top-of-funnel optimizado para volumen de búsqueda.
La arquitectura de datos que hace falta
Conectar contenido con pipeline requiere tres piezas técnicas que muchas organizaciones todavía no tienen integradas. Primero, identificación de visitantes anónimos que se resuelve cuando el contacto se identifica más adelante (formulario, evento, demo). Herramientas como Segment, RudderStack o una implementación propia con first-party cookies y server-side tracking resuelven esto razonablemente bien.
Segundo, un modelo de atribución que viva en el data warehouse, no en la interfaz de Google Analytics. BigQuery o Snowflake con dbt para las transformaciones permiten construir tablas de touchpoints por contacto y oportunidad que después se cruzan con el CRM. Tercero, un job programado que actualice estas métricas semanalmente y las exponga en el dashboard que mira el equipo de contenido. Si los redactores tienen que pedir el dato a analytics, el dato no se usa.
El coste de montar esto suele estar entre 15.000 y 40.000 euros de implementación inicial, dependiendo del estado del stack actual. La mayoría de equipos lo recuperan en uno o dos trimestres porque dejan de producir contenido que no contribuye al negocio.
Qué cambia en la operación de contenido
Cuando estas métricas están en sitio, los briefs de contenido cambian. En lugar de partir de un keyword con volumen de búsqueda, parten de un cluster que históricamente convierte y de una pregunta que comerciales escuchan en discovery calls. El calendario editorial deja de ser una lista de temas y se convierte en una matriz de cluster, intención de compra y formato.
También cambia la conversación con ventas. Cuando el equipo de contenido puede mostrar que tres artículos específicos aparecen en el journey del 40% de las oportunidades cerradas en EMEA, ventas empieza a pedir piezas concretas para casos de uso concretos. Eso es operativamente distinto a “necesitamos más contenido”. Y cambia el criterio de éxito de los redactores, que pasan de medir publicaciones por mes a medir contribución a pipeline por pieza.
Por dónde empezar sin reescribir el stack
Una primera iteración útil se puede hacer en cuatro semanas con lo que ya hay. Exportar los últimos 18 meses de oportunidades del CRM, cruzarlas con los datos de sesión de las