El 9 de junio, Anthropic lanzó Claude Fable 5. Estado del arte en casi todos los benchmarks. El modelo más capaz que habían puesto a disposición general. Tres días después, los controles de exportación de Estados Unidos cortaron el acceso global. Durante tres semanas, el mejor modelo de IA disponible en el planeta no estuvo al alcance de la mayor parte del mundo.
Volvió el 1 de julio con nuevas salvaguardas: un clasificador de ciberseguridad, consultas sensibles derivadas a un modelo más pequeño, y lo que Anthropic llama guardarraíles “extraordinariamente sólidos”.
El episodio merece atención. No por lo que dice sobre Fable 5, sino por lo que revela sobre un cambio estructural en cómo se distribuye la capacidad de IA.
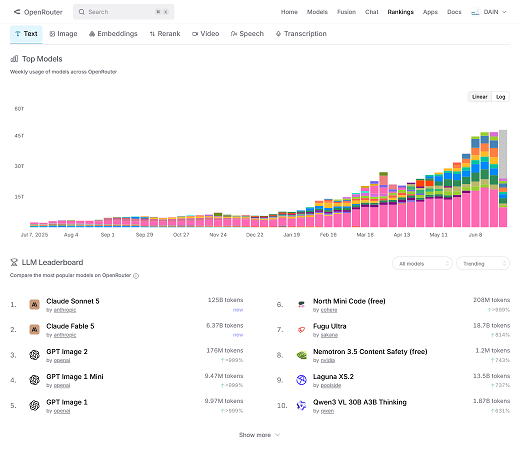
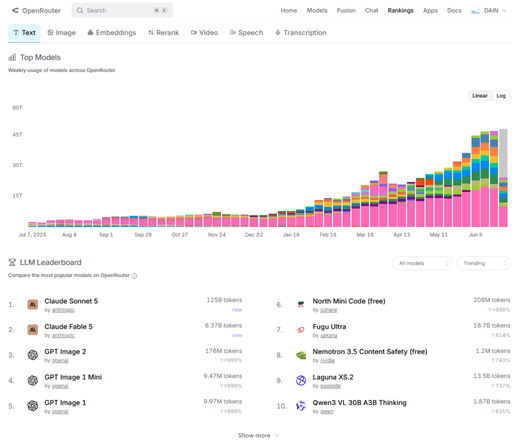
Ranking de modelos LLM de OpenRouter, julio 2026. Claude Sonnet 5 ocupa el puesto 1 con 125.000 millones de tokens procesados. Fable 5, pese a estar tres semanas fuera de servicio, alcanzó el puesto 2 pocos días después de volver.
El mercado se está dividiendo en dos
OpenRouter procesa ahora unos 100 billones de tokens al mes entre 8 millones de usuarios. Los datos muestran un mercado que se bifurca en dos carriles claros.
Carril commodity: modelos por debajo de 1 dólar por millón de tokens. Salen modelos nuevos cada diez días. Los modelos chinos (DeepSeek, MiniMax, la familia Qwen de Alibaba) pasaron de menos del 2% del tráfico de OpenRouter hace un año al 45% hoy. North Mini Code de Cohere es gratuito. Llama 4 Scout procesa contexto largo a 0,10 dólares por millón de tokens.
Carril frontera: un puñado de modelos que mantienen precios premium. Claude Fable 5 a 10/50 dólares por millón de tokens. Opus 4.8 a 5/25. Estos modelos justifican su coste con un rendimiento medible distinto en tareas complejas: razonamiento extendido, generación de código en bases de código grandes, síntesis de varios pasos que los modelos commodity todavía no resuelven bien.
Los precios han caído aproximadamente un 80% desde principios de 2025. La trayectoria apunta a una reducción de 10 veces cada 18 meses. Pero hay algo que la tendencia de precios oculta: tokens más baratos no se traducen automáticamente en costes más bajos.
La lección de Uber
La experiencia de Uber lo ilustra. Claude Code pasó del 32% al 84% de adopción entre sus aproximadamente 5.000 ingenieros. Coste mensual por ingeniero: entre 500 y 2.000 dólares. Uber agotó todo su presupuesto de IA de 2026 en cuatro meses.
Los precios cayeron un 80%. El consumo creció más rápido.
Esto no es un problema exclusivo de Uber. Es un patrón estructural. Cuando las herramientas de IA se vuelven genuinamente útiles, el uso se expande hasta llenar cualquier presupuesto disponible, y luego lo supera. Las organizaciones que controlan costes no son las que encuentran modelos más baratos. Son las que dirigen cada consulta al modelo correcto, en el nivel correcto.
El cuello de botella real es la gobernanza, no la capacidad
En junio pasaron tres cosas que parecen no tener relación pero apuntan a la misma conclusión:
- Fable 5 desapareció durante tres semanas por una decisión gubernamental, no por un fallo técnico.
- Los modelos chinos pasaron del 2% al 45% del mayor mercado de modelos en doce meses.
- Uber demostró que los tokens más baratos no controlan los costes cuando la adopción va por delante de la arquitectura.
El hilo común: la capa de modelos se está convirtiendo en commodity y desestabilizando al mismo tiempo. Los precios bajan, las opciones se multiplican, y el acceso se puede cortar de un día para otro.
El cuello de botella técnico en IA ya no es la capacidad. Es la gobernanza: quién tiene acceso, bajo qué condiciones, y con qué velocidad pueden cambiar las reglas.
Intelligence Infrastructure: la capa que importa
Las organizaciones que van a operar bien en este entorno son las que construyen lo que llamamos Intelligence Infrastructure: la capa operativa persistente entre los equipos y los modelos. Esta capa decide qué modelo se encarga de qué tarea, conmuta automáticamente cuando un proveedor deja de estar disponible, y mide el coste por resultado en lugar del coste por token.
El modelo es reemplazable. El criterio sobre cómo usarlo no lo es.
Una hoja de referencia práctica de enrutamiento (julio 2026)
- Razonamiento de frontera (síntesis compleja, generación de código extensa): Claude Fable 5 (10/50 $/M) u Opus 4.8 (5/25 $/M)
- Programación y análisis diario: Claude Sonnet 5 (3/15 $/M) o DeepSeek V4-Pro (0,46/0,92 $/M)
- Enrutamiento de alto volumen, clasificación, triaje: Gemini 2.5 Flash (0,075 $/M) o Haiku 4.5 (1/5 $/M)
- Ingesta de contexto largo (10M+ tokens): Llama 4 Scout (0,10/0,30 $/M)
Precios de OpenRouter, julio 2026.
Qué significa esto para tu equipo
Si tu operación de IA depende de un único modelo de un único proveedor, el episodio de Fable 5 debería hacerte pensar. No porque Anthropic haya hecho algo mal. Porque cualquier dependencia de un solo proveedor es un riesgo estructural en un mercado que se mueve tan rápido.
La pregunta no es “¿qué modelo deberíamos usar?” La pregunta es: ¿quién en tu organización decide qué modelo se encarga de qué tarea, y qué pasa cuando uno de ellos deja de estar disponible?
Si la respuesta no está clara, esa es la conversación que vale la pena tener este mes.
Si tu situación encaja con esto, podemos ayudarte. 15 minutos, sin diapositivas, solo el problema.